What Is Lossless Compression? Learn Its Benefits Today
Understanding What Is Lossless Compression at Its Core
Imagine you have a 1000-piece puzzle that you need to put back into its box. The goal is to fit every single piece without breaking or losing a single one. Lossless compression is the digital version of this process—it’s a way to reorganize data so it takes up less space, with the guarantee that when you unpack it, every piece of information is perfectly restored. This isn't just about shrinking files; it's about making them more efficient while keeping their digital integrity completely intact.
At its heart, this technology is a clever form of data shorthand. Instead of throwing information away, it finds smart ways to represent it more efficiently. Think of it like a sharp editor reviewing a long manuscript. If the phrase "the United States of America" appears hundreds of times, the editor might replace it with "USA" and add a note in the glossary: "USA = the United States of America." The document gets shorter, but the original meaning is fully preserved. Lossless algorithms do something similar with data by identifying and shortening repetitive patterns.
The Principle of Perfect Reconstruction
The main promise of lossless methods is perfect reconstruction. This means the original data can be put back together exactly from the compressed file, with zero information lost. The technique works by finding and using the statistical patterns found in most data, which allows for a smaller file size while keeping every original bit. This is the key difference from lossy compression, which permanently discards some data to make files even smaller. For a more detailed explanation, you can find more information on Wikipedia's lossless compression page.
This distinction is critical for many uses. For instance, a simple visual can show how lossless compression saves every pixel.

The image above shows that after lossless compression and decompression, the final output is identical to the original, down to the last pixel. This visual proof demonstrates the method's reliability, ensuring no quality is ever sacrificed for space savings.
Why This Matters in a Data-Driven World
Understanding what lossless compression is helps us appreciate the technology that quietly supports much of our digital lives. Every time you download a software application, open a ZIP file, or work with a text document, you are depending on it. The integrity of the code in an application or the precise wording in a legal contract cannot be approximated; it must be exact.
Any change, no matter how small, could corrupt the file or make it useless. Lossless compression strikes the perfect balance: it reduces the storage and bandwidth needed without ever compromising the quality of the original data. This makes it an essential tool for everything from personal file backups to critical business systems.
The Science Behind Perfect Data Preservation
At its heart, lossless compression is about finding and encoding patterns with mathematical precision. Think of it like a clever editor who notices you've used the same long phrase thousands of times. Instead of retyping it, the editor creates a simple shortcut and a reference guide to restore the original text later. Algorithms do this at incredible speeds, spotting redundancies in millions of data points that we would never see.
This process doesn't throw any information away; it just finds a more efficient way to represent it. Because of this, every single bit of the original file can be perfectly reconstructed. How well this works, however, really depends on the type of data you're compressing.
Key Algorithmic Approaches
Lossless compression isn't one single technique but a family of them, each designed for different kinds of patterns. Most modern algorithms are built on three foundational approaches:
- Dictionary-Based Methods: These algorithms, like the well-known Lempel-Ziv (LZ) family, create a "dictionary" of repeated data sequences within a file. When a sequence appears again, the algorithm inserts a short reference pointing back to its first occurrence instead of rewriting it. This is extremely effective for text files and source code.
- Run-Length Encoding (RLE): This is a simpler but potent technique for data that has long, repeating strings of the same value. For example, instead of storing "WWWWWW," RLE saves it as "6W." It's especially useful for simple graphics and images where large areas share the same color.
- Entropy Coding: This advanced method, which includes Huffman coding, assigns shorter binary codes to symbols that appear frequently and longer codes to those that appear less often. It fine-tunes data storage based on probability, achieving significant size reduction across many file types without losing any information.
To better understand how these methods perform, it's helpful to see them in action. The table below breaks down popular lossless compression techniques, their methods, and where they excel.
Popular Lossless Compression Methods Explained
Understanding different approaches to lossless compression, their strengths, typical performance, and ideal applications
| Method | How It Works | Compression Ratio | Best For | Common Examples |
|---|---|---|---|---|
| LZ77/LZ78 (Dictionary) | Builds a dictionary of repeated strings and replaces them with references. | 2:1 to 3:1 | Text, source code, and general-purpose files. | ZIP, GZIP, PNG |
| Run-Length Encoding (RLE) | Replaces sequential runs of identical data with a count and a single value (e.g., "AAAAA" becomes "5A"). | Varies greatly (high for simple images) | Simple graphics, icons, and bitmap images with large color blocks. | PCX, BMP, TIFF |
| Huffman Coding (Entropy) | Assigns shorter codes to frequent symbols and longer codes to infrequent ones based on statistical probability. | 1.5:1 to 2.5:1 | A wide range of data, often combined with other methods. | JPEG (lossless mode), MP3 (part of the process) |
| FLAC (Audio Specific) | Uses a combination of RLE and predictive modeling tailored for audio waveforms. | 1.5:1 to 2:1 (approx. 40-60% of original size) | High-fidelity audio, music archives, and professional audio production. | FLAC audio files |
| PNG (Image Specific) | Combines DEFLATE (LZ77 + Huffman) with pre-compression filters to optimize image data. | 1.5:1 to 2:1 (approx. 50-70% of original size) | Web graphics, logos, and images requiring transparency and perfect detail. | PNG image files |
As the table shows, there's no single "best" method—the right choice depends entirely on the file's content. Text files and audio signals have very different patterns, which is why specialized algorithms like FLAC and PNG were developed to deliver superior results for their specific data types.
The infographic below gives a general idea of the size reduction you can expect for different kinds of files.
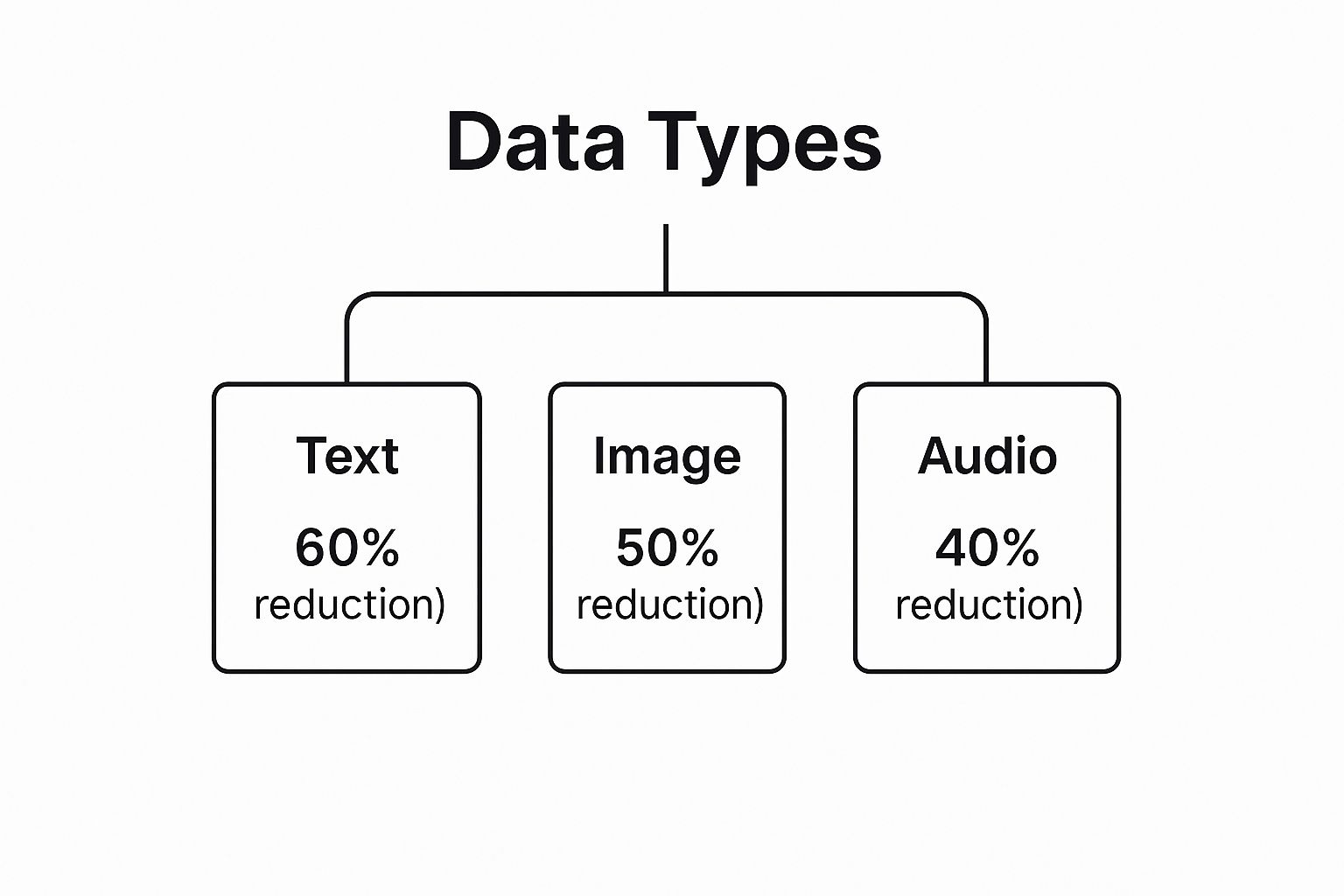
This visual underscores how a file's internal structure—from the high repetition in text to the more intricate patterns in audio—directly affects how much it can be compressed. Some files shrink dramatically, while others barely change. It all comes down to the smart mathematical rules that guarantee a perfect restoration every time.
Lossless vs. Lossy: Making The Right Choice Every Time
The decision between perfect quality and smaller file sizes plays out millions of times every day. It's a lot like choosing between keeping every single word of an important contract versus getting a quick summary. Lossy compression is like a friend who gives you just the movie highlights—you get the main plot, but you might miss some of the subtle, important details. Lossless compression, on the other hand, acts like a photographic memory, recalling every single detail with perfect accuracy.

This difference is critical in many real-world situations. A software developer, for instance, cannot afford to have a single bit of code altered, as it could break an entire application. Similarly, professional photographers need to find a balance between preserving pristine image quality for their clients and managing storage costs. Even your personal data backups require a different approach than the media you stream online.
When to Choose Each Method
The choice between lossless and lossy compression really comes down to one question: what is more important, quality or file size? If preserving every last bit of the original data is non-negotiable, then lossless is your only real option. This is the standard for:
- Source code and executable files: Any change to the data would be catastrophic, rendering the program useless.
- Medical imaging and scientific data: Precision is paramount, and no level of approximation is acceptable.
- Text documents and archives: The integrity of words, numbers, and official records must remain absolute.
Lossy compression is the better choice when file size and transfer speed are more important than perfect fidelity. It works best in situations where a small amount of data loss is unnoticeable to the human eye or ear. This is especially true in fields like cloud gaming, where high visual quality must be balanced with real-time performance. You can see this in action by learning about Pixel Streaming Explained: The Future of Cloud Gaming, where the user experience depends on this trade-off.
To make this choice clearer, the table below provides a direct comparison to help you decide which approach is right for your needs.
Lossless vs. Lossy: The Complete Comparison
Side-by-side analysis of lossless and lossy compression to help you choose the right approach for your specific needs
| Factor | Lossless | Lossy | Decision Guide |
|---|---|---|---|
| Data Integrity | 100% of original data is preserved. The file can be restored perfectly. | Some data is permanently discarded. Original quality is lost. | Choose lossless for files where any data change is a failure (code, text, medical data). |
| File Size Reduction | Moderate reduction, typically 20-50%. | Significant reduction, often up to 90% or more. | Choose lossy when you need small file sizes for storage or fast transfers (web images, streaming). |
| Reversibility | Fully reversible. You can always get the original file back. | Irreversible. Once the data is gone, it cannot be recovered. | Lossless is essential for archives and master copies. Lossy is fine for distribution copies. |
| Best For | Text, source code, archives, technical drawings, medical records. | Web images, streaming video, online audio, casual photography. | Match the method to the file's purpose. Is it for storage and accuracy, or for speed and convenience? |
Ultimately, understanding the difference between what is lossless compression and its lossy counterpart gives you complete control over your data. It allows you to make informed decisions that align with your specific goals. For those looking for advanced compression, exploring tools that support both methods is a wise step. You can see how this works by checking out our guide on the 10 reasons Compresto outperforms other compression tools. This knowledge empowers you to manage your digital assets effectively, ensuring you make the right choice every time.
From NASA Missions To Your Hard Drive: A Technology Journey
The lossless compression technology that lives on your computer has a thrilling backstory, shaped by fierce corporate rivalries, open-source ingenuity, and even the demands of space exploration. This journey from patent battles to interplanetary missions shows how high-stakes problems drive huge leaps in technology.
The story of these algorithms goes back decades, but things really heated up in the 1980s and 1990s. An early star was the LZW (Lempel-Ziv-Welch) algorithm, which became the standard for UNIX systems and the GIF image format. But there was a catch: LZW was patented. This forced the tech community into a tough spot—either pay hefty licensing fees or invent something better. This legal pressure became a powerful motivator for creating new, open alternatives. You can find a detailed history of these competing technologies on the Engineering and Technology History Wiki.
From Patent Wars to Open Standards
This difficult situation ultimately led to the creation of algorithms that are still essential today. The open-source world, wanting to break free from patent fees, went to work on more powerful and accessible options. Two of the most important innovations to emerge were:
- DEFLATE: This smart algorithm, which combines LZ77 and Huffman coding, became the powerhouse behind the popular
gziptool and the ZIP file format. It delivered great compression performance without the legal headaches of LZW. - Burrows-Wheeler Transform: A more advanced algorithm used in
bzip2, it often achieves even better compression than DEFLATE, especially with large text files. It works by cleverly rearranging data to make it easier to compress.
This was more than just a workaround to avoid fees; it was a push toward open technology that anyone could use, share, and improve. This movement laid the groundwork for many of the essential tools we depend on today.
The Ultimate Testing Ground: Space Exploration
While patent disputes raged on Earth, lossless compression was already proving its incredible value in the most unforgiving environment imaginable: outer space. For an agency like NASA, data integrity is not just a priority—it's everything. Since the late 1960s, every single bit of data from probes, rovers, and satellites has been sent back to Earth using lossless methods.
Think about transmitting images from Mars or critical telemetry from a probe traveling through deep space. If even one pixel or a single data point were lost, a priceless scientific discovery or a multi-billion-dollar mission could be jeopardized. There's no margin for error. The very same algorithms that now compress your software updates were first proven in scenarios where failure was simply not an option. This incredible legacy of reliability is now a fundamental part of your everyday software.
Where Perfect Data Can't Be Compromised
While smaller file sizes are great for convenience, some data is simply too important to lose even a single bit. These applications form an invisible backbone of our digital society, where using lossless compression isn't a choice but a necessity. In these high-stakes fields, perfect data preservation is the foundation of trust and safety.

Mission-Critical Applications
In certain industries, even the tiniest data change can have disastrous outcomes. Lossless compression is the standard in these scenarios to guarantee that the decompressed file is mathematically identical to the original.
- Medical and Healthcare: Hospitals rely on lossless methods for medical images like X-rays, CT scans, and MRIs. A single corrupted pixel could hide a critical diagnostic detail, while a misplaced decimal in a patient's electronic health record could lead to the wrong medication dosage. Accuracy is non-negotiable.
- Financial and Legal Sectors: Imagine if your bank's compression algorithm "approximated" your account balance. Financial institutions use lossless techniques to protect every detail of transaction records. Similarly, legal firms depend on bit-perfect document preservation for contracts and evidence, where authenticity must be beyond doubt.
- Software and Executables: When you download a software application, every single line of code must arrive intact. A minor change could cause the program to crash, behave unpredictably, or create security holes. Lossless formats like ZIP are standard for ensuring software integrity.
The Frontier of Discovery and Security
Beyond corporate and medical fields, lossless data handling is vital for scientific progress and digital security. Researchers working with years of experimental data can't afford to lose information that might be impossible to reproduce.
This need for perfect accuracy extends far beyond our planet. Lossless compression has been essential for space exploration since the late 1960s, making sure that irreplaceable data from deep space missions gets back to Earth with absolute precision. You can explore more about its role in this report on data compression for space systems.
The same principle of perfect preservation applies to something we all use: backup systems. The whole point of a backup is to create an exact copy of your data for future restoration. Using any method that alters the original data would defeat the purpose, making lossless compression the only sound choice for reliable data recovery. This focus on preservation also has positive environmental effects, a topic we explore in our article about how file compression reduces digital waste. These aren't just technical choices; they are the bedrock of trust in our digital infrastructure.
Smart Strategies for Choosing Lossless Compression
Deciding on lossless compression isn't just a technical choice; it’s a strategic decision that involves balancing different business needs. The benefits go far beyond just keeping your data intact. Think reduced long-term storage costs, more dependable data transfers over shaky networks, and easier compliance with regulations. But these advantages come with trade-offs, like larger file sizes and more demanding processing requirements.
Every day, professionals have to weigh these factors. It's a constant negotiation between bandwidth, storage budgets, processing power, and how valuable the data is over time. The fundamental question is always: Is perfect data preservation worth the extra overhead? For a surprising number of uses, the answer is a clear yes.
A Decision-Making Framework
To make the right call, it helps to have a clear framework. These points will help you figure out when lossless compression offers the best return on your investment.
- Data Criticality: Is the data for legal, archival, or mission-critical use? If even a tiny change could cause financial loss, legal problems, or system failure, lossless is the only safe bet.
- Storage vs. CPU Costs: Lossless compression typically uses less processing power than complex lossy algorithms but creates larger files. You need to decide which is more precious to your budget: storage space or CPU time.
- Network Conditions: If you’re sending data over unreliable or slow networks, the integrity guarantee from lossless methods can save you from the hassle and cost of retransmitting files due to corruption.
- Use Case and Lifespan: Is this a master file or a copy for distribution? Master files, like an original video edit or an unedited photograph, should always be kept in a lossless format. Copies meant for web streaming or social media can often use lossy compression to save space and speed up loading.
The table below breaks down common situations to help guide your choice.
| Scenario | Primary Concern | Recommended Strategy | Rationale |
|---|---|---|---|
| Medical Imaging Archive | Absolute Accuracy | Lossless | Diagnostic precision and patient safety rely on pixel-perfect data. |
| Website Image Delivery | Page Load Speed | Lossy | Faster loading improves user experience and search engine ranking. |
| Software Distribution | Program Integrity | Lossless | A single corrupted bit can cause installation failures or application crashes. |
| Cloud Data Backup | Data Recoverability | Lossless | Ensures that your backup is an exact, restorable copy of the original data. |
Ultimately, understanding these scenarios and knowing your priorities are what matter most. Making informed choices helps you optimize your files the right way. For more hands-on advice, check out our guide on 10 ways to optimize your files without losing quality, which provides more tips for smart file management.
What's Next For Perfect Data Preservation
As our world creates more data than ever—from complex scientific models to the constant information streams from our devices—the field of lossless compression is evolving to keep up. The main goal is no longer just to shrink files, but to do it more intelligently, quickly, and securely. This means developing new algorithms designed for the next wave of data and technology.
The Rise of AI and Specialized Algorithms
The future of perfect data preservation is getting smarter. Artificial intelligence is starting to play a major role by learning to spot complex patterns in data that older methods might overlook. This leads to better compression ratios without giving up the core promise of perfect reconstruction.
At the same time, specialized algorithms are being created to tackle new challenges:
- IoT and Sensor Data: Billions of Internet of Things devices generate non-stop streams of information. New methods are being designed to compress this continuous flow with high efficiency.
- High-Fidelity Media: With the move toward 8K video and ultra-high-resolution scientific imaging, algorithms need to manage huge datasets while preserving every single detail.
- Edge Computing: Devices like smartphones and smart cameras must process information on the spot. This creates demand for compression that offers extremely fast decompression for real-time use.
Privacy, Security, and Sustainability
Beyond raw performance, privacy has become a key focus. New research is exploring compression techniques that can work directly on encrypted data. This would allow files to be made smaller for storage or transfer without ever revealing the sensitive information they contain.
The environmental footprint of data storage is also a growing concern. More energy-efficient compression can help lower the power consumption of large data centers, making data preservation more sustainable. Understanding what is lossless compression and where it's headed is essential for anyone creating long-term data strategies in a world where perfect data preservation matters more than ever.
Ready to put powerful, quality-preserving compression to work on your Mac? Discover how Compresto can optimize your files, save space, and speed up your workflow.