Data Compression Methods Explained: Lossy vs Lossless (2026 Guide)
At its core, data compression is all about making digital information smaller. Think of it like neatly folding your clothes to save space in a suitcase or creating a shorthand for long, common words. These clever techniques shrink our files, making them faster to send across the internet and cheaper to store.
The Unseen Engine of the Digital World
Have you ever tried to imagine our digital lives without compression? It wouldn't be pretty.
A single two-hour HD movie could easily top 100 gigabytes, taking hours—or even days—to download on a normal internet connection. Storing thousands of high-resolution photos on your phone? Impossible. Sending a large presentation over email? Forget about it. Our digital world would simply grind to a halt.
Data compression is the unsung hero that makes modern life possible. It’s the core technology that:
- Lets you binge-watch shows on platforms like Netflix and YouTube.
- Makes downloading software, documents, and media a quick and painless process.
- Keeps cloud storage affordable and practical, even for terabytes of data.
- Drastically cuts down website loading times, improving the experience on virtually every site you visit.
So, how does it work? At its heart, compression is about finding and eliminating redundancy. Digital files are full of repeating patterns, just like the word "and" appears over and over in a book. Compression algorithms are experts at spotting these patterns and creating a more efficient way to represent them, much like inventing a special symbol to replace a common word.
A Brief History of Shrinking Data
This idea of shrinking information isn't new. In fact, its roots stretch all the way back to 1838 with the invention of Morse code. By assigning shorter dot-and-dash sequences to the most common letters in English, like "e" and "t," Samuel Morse created an early, brilliant form of data reduction.
The computer age saw this concept explode with algorithms like Shannon-Fano and Huffman coding in the mid-20th century. But the real software revolution kicked off with the Lempel-Ziv (LZ) algorithms in the 1970s. These introduced dictionary-based techniques that became the foundation for modern tools we use every day, like ZIP files. For a deeper dive, the Engineering and Technology History Wiki offers a fantastic timeline of these innovations.
Key Takeaway: Data compression isn't just a technical trick; it's a fundamental pillar of modern technology. By making data smaller, it makes information more accessible, shareable, and storable, powering everything from instant messaging to complex scientific research.
All compression methods are guided by two main philosophies: lossless and lossy compression. Understanding the difference between them is the first and most crucial step to mastering how this powerful technology works. We’ll explore each in detail, helping you see when perfect data integrity is non-negotiable and when a tiny, imperceptible trade-off can unlock massive benefits.
How Lossless Compression Preserves Every Detail

When you absolutely cannot afford to lose a single bit of data, lossless compression is your only option. Think of it like a perfect vacuum-seal bag for your files. When you open it back up, everything inside is in its exact original state. Not a single piece of information is lost or altered.
This level of precision is non-negotiable for certain types of data. Imagine trying to compress a critical software application or a legal contract. If even one byte changed, the program would crash or the document would be corrupted. Lossless techniques guarantee this never happens by cleverly reorganizing data, not discarding it. It's the go-to method for text files, executable programs, and scientific data where absolute fidelity is paramount.
Let's look at three foundational algorithms that show the brilliant—and very different—ways lossless compression achieves this perfect reconstruction.
Run-Length Encoding (RLE)
One of the most intuitive data compression methods is Run-Length Encoding (RLE). It works on a dead-simple principle: find consecutive runs of the same data and replace them with a single data value and a count. It’s a simple way of saying, "this character, this many times."
For instance, consider a simple line in a black-and-white image. A long white stripe might be stored as a string of pixels like this:
WWWWWWWWWWWWBBBBWWWWWWWW
RLE shrinks this down by simply counting the repeats. The compressed version looks something like 12W4B8W. It conveys the exact same information but uses far fewer characters. This straightforward approach makes RLE incredibly effective for simple graphics and icons that have large areas of solid color.
But there's a catch. Its effectiveness depends entirely on the data's structure. If you try to use RLE on data without long repeating runs—like a complex photograph or a novel—it can actually make the file size larger.
Huffman Coding
Where RLE looks for repeating sequences, Huffman Coding plays the odds. Developed by David Huffman back in 1952, this clever technique assigns shorter binary codes to characters that appear frequently and longer codes to those that show up less often. It’s like creating a shorthand where common words get tiny symbols and rare ones get longer ones.
Think about the English language. The letter 'E' appears far more often than 'Z'. In a standard system like ASCII, both letters take up the same amount of space (8 bits). Huffman Coding analyzes a file first to see which characters are the most common.
In this system, 'E' might get a short code like
01, while 'Z' gets a much longer one, such as11101001. Across an entire document, these tiny savings for each character add up to a significant reduction in the total file size.
This method is highly effective for text-based files where character frequencies follow predictable patterns. It’s so useful, in fact, that it forms a core part of other major compression standards, including the DEFLATE algorithm used in PNG images and ZIP archives.
Lempel-Ziv-Welch (LZW)
Taking a completely different route, Lempel-Ziv-Welch (LZW) is a powerful, dictionary-based algorithm. Instead of analyzing character frequency, it builds a dictionary of recurring strings and patterns on the fly as it reads a file. When a pattern it has already seen repeats, LZW simply replaces it with a short reference to its dictionary entry.
Imagine compressing a report that repeatedly uses the phrase "data compression methods". The first time LZW encounters this phrase, it adds it to its dictionary and assigns it a short code, maybe 452. The next time this exact phrase appears, LZW just writes the code 452 instead of the full 24 characters.
This adaptive approach is incredibly versatile and works well on a huge range of data types. It was the magic behind older image formats like GIF and TIFF and was a foundational technology for many early file archivers. Its ability to learn the specific patterns within any given file makes it one of the most widely implemented lossless techniques.
Choosing between these methods—or the tools that use them—depends on your specific file and your goals. You can see how this plays out by exploring the 10 reasons Compresto outperforms other compression tools, as great performance often comes down to leveraging the right algorithm for the job. No matter which one is used, each of these lossless methods guarantees perfect data fidelity, ensuring what you compress is exactly what you get back.
How Lossy Compression Makes Media Manageable

While lossless compression is all about perfect preservation, lossy compression plays a different game. It makes a smart trade-off: it throws away tiny, often unnoticeable bits of information to drastically shrink file sizes. This is the magic that makes our modern media world possible, from streaming high-definition movies to sharing photos in an instant.
Think of it like an impressionist painting. The artist isn’t trying to capture every single ripple in the water with perfect, photographic detail. Instead, they capture the feel of the scene—the light, the color, the overall mood. Your brain happily fills in the rest, and the result is a complete and powerful image. Lossy data compression methods do the exact same thing for our photos, videos, and music.
This approach is tailor-made for media where perfect, bit-for-bit accuracy isn't the main goal. Losing a few pixels from a photo usually goes unnoticed, but losing a few numbers from a bank record would be a disaster. The result is a much smaller file that, to our eyes and ears, looks and sounds almost identical to the original.
The Magic of Transform Coding and DCT
One of the cleverest tricks behind lossy compression is transform coding. Instead of seeing a file as a simple grid of pixels or a string of sound waves, this technique converts the data into a whole new format—one based on frequencies and patterns. The most famous example of this is the Discrete Cosine Transform (DCT), which is the engine that powers the JPEG image format.
DCT works by analyzing small blocks of an image (usually 8x8 pixels) and separating the crucial, low-frequency information (like large areas of color) from the less important, high-frequency details (like fine textures). It turns out that most of what makes an image recognizable is concentrated in just a few of these low-frequency components.
This transformation is brilliant because it perfectly sets the stage for the next step, which is where the real "lossy" action happens.
Key Insight: Transform coding doesn't actually compress the data on its own. It just rearranges the information so it becomes incredibly easy to spot—and discard—the parts our eyes are least likely to miss.
Quantization: Throwing Away What Doesn't Matter
Once the DCT has sorted the image data into important and not-so-important frequencies, quantization steps in. This is the part of the process where data is intentionally discarded. It aggressively reduces the precision of the high-frequency components—those subtle details our eyes barely notice—while carefully preserving the essential low-frequency information.
Imagine you have a list of numbers like 10.134, 18.892, and 4.321. Quantization might round them off to 10, 19, and 4. You’ve lost a bit of precision, but the core values are still there. In a JPEG, this is done much more heavily on the parts of the image you won't miss, leading to massive savings in file size. Best of all, the level of quantization is adjustable, giving you direct control over the balance between file size and quality.
This development was a game-changer. The discrete cosine transform (DCT), first theorized in the early 1970s, became the foundation for the JPEG standard in 1992. This approach routinely hits compression ratios of 10:1 or higher, letting a 9 MB photo shrink to less than 900 KB with almost no visible difference. You can explore the historical development of data compression on Wikipedia to see how these algorithms have shaped our digital lives.
Exploiting Human Perception
The most sophisticated lossy algorithms take things even further by tapping into the science of human perception. These psychoacoustic (for audio) and psychovisual (for images) models are built on a deep understanding of what our senses can and can't perceive.
Here’s how they work their magic:
- For Audio (MP3): Psychoacoustic models know that a loud trumpet blast will completely drown out a soft background noise that happens at the same time. The MP3 encoder identifies these "masked" sounds and just deletes them. Why keep data your ears wouldn't have heard anyway?
- For Images (JPEG): Psychovisual models recognize that the human eye is far more sensitive to changes in brightness (luminance) than to shifts in color (chrominance). JPEGs take advantage of this by storing color information at a much lower resolution than the brightness data, which cuts down the file size dramatically without a noticeable drop in quality.
By cleverly targeting the data that our own biology would filter out, these methods achieve incredible compression. It's a perfect example of smart engineering that works with human nature, not against it, to make our digital world go 'round.
Alright, let's break down the different compression algorithms you'll run into out in the wild. Knowing the difference between lossless and lossy is a great start, but now it's time to see how these theories actually play out in the real world. We'll look at the most common methods and the file formats that depend on them.
When you're picking an algorithm, you're always playing a game of trade-offs. Some are built for pure speed, while others are laser-focused on squeezing every last byte out of a file. There’s no single "best" algorithm—just the right one for the job at hand. A web server, for instance, might care more about decompressing files quickly to serve up a webpage, while an archivist will want the absolute best compression ratio to save on long-term storage costs.
This is exactly why so many different algorithms have found their own niche and continue to coexist.
Classic Algorithms and Their Use Cases
Let's start with the foundational algorithms that power many of the files you use every single day. The "format wars" we sometimes see often boil down to which compression engine is running under the hood.
A perfect example of this is the old rivalry between GIF and PNG images. GIFs rely on Lempel-Ziv-Welch (LZW), a classic dictionary-based lossless algorithm. It's pretty good for images with big, flat areas of color but has a major limitation: a 256-color palette.
PNG, on the other hand, uses a much more sophisticated two-step method called DEFLATE. This algorithm cleverly combines the LZ77 algorithm (a cousin of LZW) with Huffman coding. This one-two punch allows it to get much better compression than LZW for most graphics—without any color limits. This is why PNG became the superior lossless choice for web graphics like logos and icons.
Then you have the heavyweight champion of lossy compression: JPEG. It plays a completely different game, using a strategy based on the Discrete Cosine Transform (DCT) and quantization. This makes it unbeatable for shrinking photos and complex digital art where you don't need perfect pixel-for-pixel accuracy. The visual trade-off is often so small you can't even see it, but the file size reduction is massive, often hitting a 10:1 ratio or even better.
Modern Algorithms for Web and Data
As our data needs have grown, so have our algorithms. The demands of modern web traffic and massive data storage have pushed developers to invent even smarter methods. Two of the most important new players on the scene are Brotli and Zstandard.
-
Brotli: Developed by Google, Brotli is a lossless algorithm that consistently achieves better compression ratios than the old-school GZIP (which also uses DEFLATE). It's now baked into every major web browser and is a key reason why modern websites load so quickly—it shrinks all the HTML, CSS, and JavaScript files before they ever get to you.
-
Zstandard (Zstd): Created at Facebook, Zstd is all about speed. It was designed for incredibly fast compression and decompression while still delivering great compression ratios. Its amazing flexibility has made it a favorite for real-time applications, databases, and just about any general-purpose data compression task you can think of.
One study comparing algorithms found that GZIP using Dynamic Huffman tables reached a compression ratio of 3.11, while Zstandard was right there with it at 2.79. This really shows how competitive and specialized modern algorithms have become.
A Head-to-Head Comparison
To make a smart decision, you need a clear picture of what each algorithm does best. The right choice always comes down to what you care about most: the final file size, the speed, or the type of data you’re working with.
Here’s a quick rundown to help you see the key differences at a glance.
Practical Comparison of Common Compression Algorithms
| Algorithm | Type (Lossless/Lossy) | Best For | Key Feature |
|---|---|---|---|
| JPEG | Lossy | Photographic Images, Digital Art | Excellent compression for complex images by discarding imperceptible visual data. |
| DEFLATE (PNG/GZIP) | Lossless | Web Graphics, Text, Archives | A powerful combination of LZ77 and Huffman coding that provides a great balance of speed and ratio. |
| LZW (GIF/TIFF) | Lossless | Simple Graphics, Early Formats | A classic dictionary-based approach, effective but largely superseded by DEFLATE. |
| Brotli | Lossless | Web Assets (HTML, CSS, JS) | Offers superior compression ratios to GZIP, helping accelerate modern web performance. |
| Zstandard (Zstd) | Lossless | Real-time Data, Databases | Extremely fast compression and decompression speeds, making it ideal for high-throughput systems. |
Think of this table as your cheat sheet. Once you understand these core differences, it becomes obvious why the photo from your camera is a JPEG, your company's logo is a PNG, and that software you just downloaded came in a ZIP archive. Each one uses the right tool for the job.
Data Compression in Real-World Scenarios

Theories and algorithms are one thing, but the real magic of data compression happens when it's put to work in high-stakes, real-world situations. We're talking about environments where every single byte counts. It goes way beyond just making your favorite website load a bit faster—compression is a mission-critical technology that enables breakthroughs in science, medicine, and business.
Let's look at some fascinating examples that show just how indispensable data shrinking has become.
Beaming Data Across the Solar System
One of the most incredible use cases is in space exploration. Imagine you're a NASA engineer trying to pull a high-resolution photo from the Mars rover. The bandwidth is painfully limited, and the signal takes minutes, sometimes hours, to travel millions of miles back to Earth.
Without powerful compression, transmitting the massive amounts of data and imagery that spacecraft collect would be flat-out impossible. Space agencies have been relying on it since the 1960s to make their missions feasible, using both lossless and lossy techniques to squeeze every last bit of information from telemetry systems and scientific instruments.
We're talking about planetary missions that generate gigabits of data per day. Effective compression isn't a "nice-to-have" in this context; it's an absolute necessity.
Protecting Life-Saving Medical Data
Closer to home, the medical field provides another critical example. When an MRI machine, CT scanner, or digital X-ray creates an image, it's typically stored in a format called DICOM (Digital Imaging and Communications in Medicine). For a radiologist, having a perfectly accurate image isn't just important—it's a matter of life and death.
A tiny artifact or a single missing pixel, introduced by a sloppy lossy algorithm, could easily obscure a tumor or a hairline fracture. That kind of error could lead directly to a misdiagnosis.
This is exactly why the medical industry relies almost exclusively on lossless compression for any kind of diagnostic imaging. It ensures that when a doctor pulls up a patient's scan, they are seeing a perfect, bit-for-bit replica of the data captured by the machine. The compression ratios might be more modest, but the guarantee of absolute data integrity is non-negotiable.
Powering Modern Business and Finance
The business world also leans heavily on compression to manage the ever-growing mountains of data it produces. Large-scale database systems use it to cut down on storage costs and, just as importantly, improve query performance. By shrinking the data on disk, more of it can be read into memory faster, which speeds up everything from analytics to reporting.
In financial data archiving, integrity and efficiency are partners in crime. Regulations often demand that companies store transactional records for years. Using lossless compression makes this long-term storage far more affordable and manageable. It's a key part of effective information life cycle management, which relies on compression to handle huge volumes of data from its creation to its final archival.
These case studies truly highlight the remarkable versatility of data compression. Whether it's beaming images across the solar system, protecting crucial medical records, or optimizing a corporate database, these techniques are the quiet heroes working behind the scenes.
And there’s a bonus: by making data storage and transfer more efficient, compression also has a positive environmental impact. Check out our guide on how file compression reduces digital waste to learn more about the eco-friendly side of this technology.
How to Choose the Right Compression Method
Picking the right compression strategy isn’t about finding a single “best” algorithm. It's more like choosing the right tool for the job. The perfect choice depends entirely on your data and what you’re trying to achieve. To make a confident decision, you really just need to ask yourself a few key questions.
First and foremost: is perfect, bit-for-bit data integrity non-negotiable?
If you're compressing source code, a legal document, scientific data, or a database backup, the answer is always yes. For these files, you have to use a lossless method like DEFLATE (found in ZIP and PNG files) or Zstandard. Even the tiniest change would corrupt the file and make it totally useless. Sacrificing quality for a smaller size simply isn't an option here.
On the other hand, if you're working with media—say, a photograph for a blog post or an audio file for a podcast—a small, often unnoticeable drop in quality is usually a fantastic trade-off for a huge reduction in file size. This is where lossy methods like JPEG and MP3 really shine.
Navigating Your Priorities
Once you've made the lossless vs. lossy decision, your choice is guided by performance. Do you need the absolute highest compression ratio possible to save on long-term storage costs? Or do you need blazing-fast decompression speed for a real-time application?
Modern algorithms often specialize in one or the other. For instance, Brotli offers a fantastic compression ratio, which makes it perfect for shrinking web assets to speed up page loads. Zstandard, however, is all about incredible speed, which is why it's a favorite for databases and systems that need to handle data on the fly.
This simple decision tree can help you visualize the path to the right data compression method for your needs.
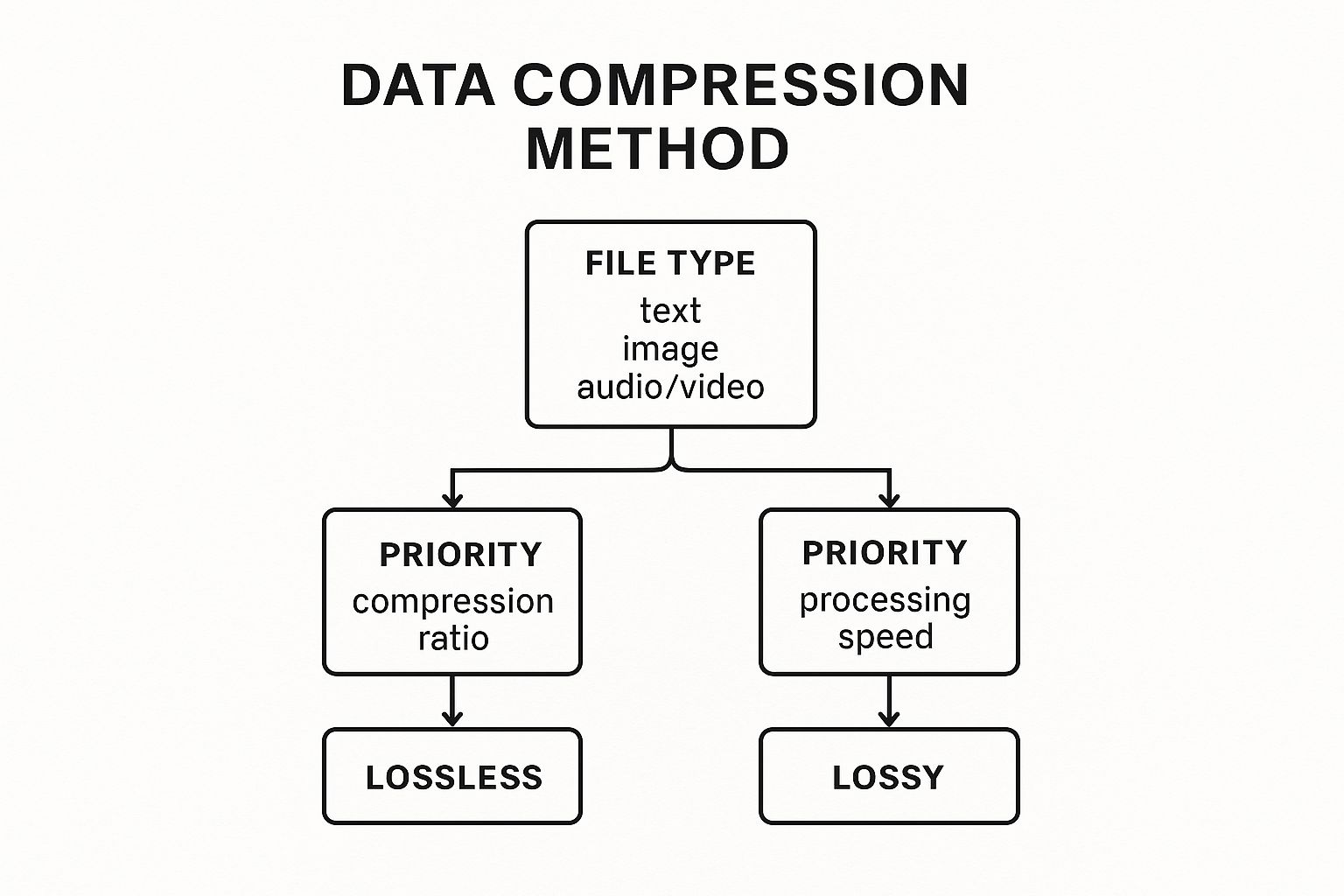
As the chart shows, your file type is the first gate. From there, you just have to decide whether data preservation or file size is your top concern.
The Decision Framework: Choosing a compression method really just boils down to a three-step process:
- Assess Your Data: First, figure out if your data (text, images, video, etc.) can handle any information loss at all.
- Define Your Goal: Next, decide if your main priority is maximum size reduction or maximum speed.
- Select the Algorithm: Finally, pick a method that lines up with those needs—like PNG for lossless graphics or JPEG for lossy photos.
By following this framework, you can move from just understanding compression to applying it effectively. For more hands-on advice, you can also explore these file size reduction tips to optimize your files without losing quality, which can further guide your optimization efforts.
Frequently Asked Questions About Data Compression
We’ve walked through the what, why, and how of data compression, from the core concepts to the algorithms that make it all happen. To wrap things up, let's go over a few common questions that pop up. This should help cement your understanding of this incredibly useful technology.
What Is the Difference Between Compression and Archiving?
It's easy to mix these two up because they often happen together, but compression and archiving are totally different things. Compression is all about shrinking a file’s size. Archiving, on the other hand, is the process of bundling multiple files and folders into a single file, which makes them much easier to store and send.
A great example is a ZIP file. It’s an archive because it can hold a whole bunch of files, but it’s also compressed, using an algorithm called DEFLATE to make everything smaller. That’s why the tools that create ZIP files are often called "file archivers."
Key Distinction: Think of it this way: archiving is like putting all your clothes into one suitcase. Compression is like using vacuum-seal bags to make everything inside that suitcase take up less space. You can do one without the other, but they work great together.
Can a File Be Compressed Multiple Times?
Technically, yes, you can compress a file more than once—but it's almost always a bad idea. The first time you compress a file, the algorithm finds and eliminates all the obvious repetition. If you try to run it again on the already-compressed file, there’s usually nothing left for the algorithm to shrink.
In fact, you’ll often end up with a larger file. Why? Because the compression algorithm has to add its own header and other metadata to the file. This extra data adds a little overhead without providing any real size reduction, defeating the whole purpose.
Why Do Some Files Compress Better Than Others?
The magic of compression all comes down to one word: redundancy. Files that are full of repeating patterns are a dream for compression algorithms. Think about text documents or simple spreadsheets—they’re packed with predictable data. Lossless algorithms can work wonders here, sometimes cutting the file size by 70% or even more.
On the flip side, some files are notoriously hard to compress. This includes files that are already compressed (like JPEGs or MP3s) or files with a high degree of randomness, like encrypted data. There are simply no patterns for the algorithms to grab onto, so trying to shrink them further is a losing battle.
Ready to shrink your files without sacrificing quality? With features like folder monitoring and a simple drop-zone interface, Compresto makes professional-grade compression effortless for any macOS user. Get Compresto and optimize your workflow today!