Data Archiving Best Practices: Top Strategies for 2025
Level Up Your Data Archiving Game
Want to master your data? This listicle provides eight data archiving best practices to streamline your workflows and protect your vital information. Learn how to establish effective lifecycle management policies, implement secure storage solutions, ensure data integrity, and optimize for accessibility and future use. Whether you're a corporate professional, Mac user, or content creator seeking efficient file management, these data archiving best practices will help you reduce costs, maintain compliance, and safeguard your valuable data.
1. Establish Clear Data Lifecycle Management Policies
Effective data archiving begins with establishing clear data lifecycle management (DLM) policies. This crucial first step in data archiving best practices provides a comprehensive framework that dictates how data is handled from its creation to its eventual disposal. A well-defined DLM policy acts as a roadmap, outlining specific timelines, retention requirements, and archival triggers, ensuring systematic and compliant data handling throughout its entire lifecycle. This practice isn't just a best practice; it's the foundation for a robust and sustainable archiving strategy.
DLM policies incorporate automated lifecycle transitions based on pre-defined rules. For example, data might automatically move from primary storage to a less expensive archival tier after a specified period of inactivity. Clear retention schedules, tailored to different data types, dictate how long specific data must be retained based on legal, regulatory, or business requirements. These policies also integrate with legal and compliance frameworks, ensuring adherence to regulations like GDPR, HIPAA, or SOX. Regular policy review and updates are essential to adapt to evolving legal landscapes and business needs. Finally, role-based access controls throughout the data lifecycle ensure that only authorized personnel can access and modify data at each stage.
Several features contribute to the effectiveness of DLM policies. Automated lifecycle transitions, driven by predefined rules, streamline data movement and reduce manual intervention. Clear retention schedules, specific to different data types, provide clarity and ensure compliance. Integration with legal and compliance requirements minimizes risks. Regular policy reviews and updates keep the framework current and aligned with best practices. And role-based access controls maintain data security and integrity throughout its lifecycle.
Implementing DLM policies offers several advantages. It ensures regulatory compliance, minimizing the risk of penalties and legal issues. It reduces storage costs by automating the movement of data to appropriate storage tiers based on its age and usage. Minimizing legal risks from data retention violations protects the organization from potential lawsuits and reputational damage. Finally, it improves data governance and accountability by providing a clear framework for data handling.
However, establishing robust DLM policies requires significant upfront planning and resources. Developing comprehensive policies requires a thorough understanding of data types, legal requirements, and business needs. Frequent updates might be necessary as regulations change and business requirements evolve. Implementing these policies across diverse data types and systems can be complex, requiring careful coordination and integration.
Many organizations have successfully implemented DLM policies. Financial institutions leverage these practices for SOX compliance archives, ensuring the long-term retention and accessibility of financial records. Healthcare organizations manage HIPAA-required patient data retention through well-defined DLM policies. Government agencies adhere to NARA record-keeping requirements by implementing structured data lifecycle management frameworks.
To effectively implement DLM policies, start with a comprehensive data inventory and classification. This helps understand the types of data being managed and their respective requirements. Involve legal and compliance teams early in policy development to ensure alignment with regulatory obligations. Use metadata tagging to automate lifecycle decisions, streamlining data movement and management. Implement gradual rollouts, starting with high-risk data types, to gain experience and refine the process before expanding to the entire organization.
The following infographic visualizes the three key stages of a data lifecycle management process: Data Creation, Retention Policy, and Data Disposal.
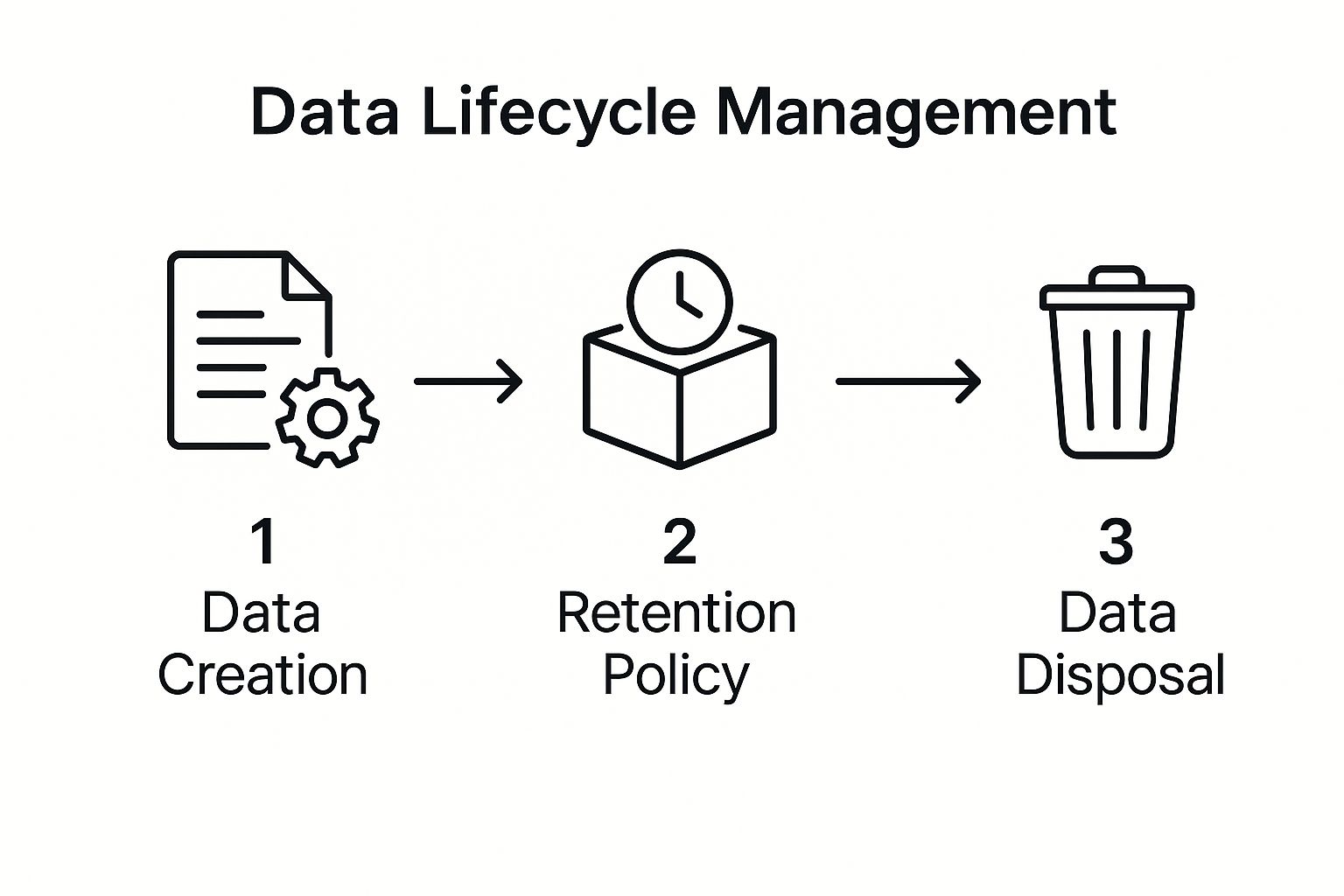
The infographic illustrates the sequential flow of data from its creation and active use, through its defined retention period, and finally to its secure and compliant disposal. This clear delineation of stages underscores the importance of a structured approach to data management throughout its lifecycle.
Popularized by organizations like NIST and contributors to the ISO 27001 framework, as well as major cloud providers like AWS, Microsoft, and Google, DLM policies are a cornerstone of modern data management. By implementing these best practices, organizations can ensure data compliance, minimize risks, and optimize storage costs.
2. Implement Multi-Tier Storage Architecture
One of the most impactful data archiving best practices is implementing a multi-tier storage architecture. This strategic approach categorizes data based on access frequency, performance needs, and cost, automatically moving it between different storage tiers. This dynamic system ensures an optimal balance between readily accessible data and cost-effective long-term storage. This isn’t just about saving money; it's about building a scalable and efficient archive that meets the diverse needs of your organization.

A multi-tiered architecture typically consists of the following:
- Hot Storage: This tier houses frequently accessed data requiring immediate availability and high performance. Think of this as your primary storage for active projects, essential databases, and frequently used applications.
- Warm Storage: Data accessed less frequently resides in warm storage. This tier offers a balance between accessibility and cost, suitable for backups, older project files, and less critical data.
- Cold Storage: Rarely accessed data, but still necessary for long-term retention, is placed in cold storage. This is ideal for archival purposes, regulatory compliance, and disaster recovery. While retrieval times are longer than hotter tiers, the significantly lower storage costs make it an excellent choice for this type of data.
- Glacier/Deep Archive: This tier caters to long-term retention of data that is rarely, if ever, accessed. Think of this as your digital vault for long-term archiving and compliance. While retrieval times can be measured in hours, the extremely low cost makes it perfect for data that needs to be preserved but isn't actively used.
Automated tiering, based on predefined policies and access patterns, forms the backbone of this architecture. Data automatically migrates between tiers, ensuring that frequently accessed data remains readily available while less active data moves to more cost-effective storage. This dynamic management optimizes both performance and cost.
The benefits of a multi-tiered architecture are numerous:
- Significant Cost Savings: By moving less frequently accessed data to lower-cost tiers, organizations can realize significant cost savings, sometimes up to an 80% reduction in storage expenses.
- Maintained Data Accessibility: Data remains accessible even when moved to colder tiers, ensuring it's available when needed, although with varying retrieval times.
- Scalability: A tiered approach scales seamlessly with data growth, accommodating increasing volumes of data without compromising performance or budget.
- Performance Optimization: Keeping frequently accessed data in hot storage optimizes performance for active projects and applications.
However, there are some potential drawbacks to consider:
- Retrieval Times: Retrieval times increase as data moves to colder tiers, ranging from minutes to hours.
- Management Complexity: Managing multiple storage systems and tiering policies can introduce some complexity.
- Retrieval Costs: Retrieving data from cold storage can incur costs, so careful planning and monitoring are essential.
Examples of successful multi-tier architecture implementation are prevalent across various industries. Netflix uses Amazon S3 Intelligent Tiering for its vast content archives, ensuring rapid access to popular content while archiving older titles cost-effectively. Banks leverage cold storage for transaction records after regulatory periods expire, maintaining compliance while minimizing storage costs. Research institutions archive large scientific datasets in glacier storage, preserving valuable research data for the long term.
Learn more about Implement Multi-Tier Storage Architecture (While this link primarily discusses video compression, it highlights tools and techniques relevant to optimizing storage usage within a tiered architecture).
To effectively implement a multi-tier storage architecture, consider these tips:
- Analyze Access Patterns: Before implementing tiering policies, thoroughly analyze your data access patterns to understand how different data sets are used.
- Monitor Retrieval Costs and Times: Closely monitor retrieval costs and times to optimize policies and avoid unexpected expenses or delays.
- Use Intelligent Tiering Services: When available, utilize intelligent tiering services that automate data movement based on access patterns. Cloud providers like Amazon Web Services, Microsoft Azure, and Google Cloud offer robust solutions.
- Plan for Emergency Access: Develop a plan for accessing data in cold or glacier storage during emergencies, ensuring business continuity.
By implementing a multi-tier storage architecture as a core data archiving best practice, you can create a cost-effective, scalable, and efficient archive that supports your current operations while preserving valuable data for the future. This approach ensures that your data is readily available when needed while minimizing storage expenses, a critical aspect of any successful data management strategy.
3. Ensure Data Integrity Through Checksums and Validation
Data archiving best practices necessitate a robust approach to maintaining the integrity of stored information. A critical component of this is ensuring data integrity through checksums and validation. This practice involves generating unique cryptographic fingerprints, known as checksums or hashes, for each data file. These fingerprints are then used to periodically verify that the archived data remains unaltered and hasn’t suffered from corruption, tampering, or degradation over time. This process ensures that your archived data stays authentic and usable throughout its entire lifecycle, a crucial requirement for any organization dealing with sensitive or valuable information. This is especially critical for data archiving best practices because archived data is often accessed less frequently, making undetected corruption a serious risk.

Checksum generation uses cryptographic hash functions like MD5, SHA-256, and SHA-512. These functions take the data as input and produce a fixed-size string of characters representing the data’s unique fingerprint. Even a minuscule change in the original data will result in a drastically different checksum, allowing you to detect even the slightest corruption. Implementing regular integrity verification schedules is key. These schedules should be based on the criticality of the data and the storage environment's stability. Automated systems can streamline this process, flagging discrepancies and triggering alerts for immediate action. Redundant checksum storage further strengthens this approach by safeguarding against the loss of checksums themselves. Ideally, checksum generation and verification should be integrated with your existing backup and recovery processes to form a comprehensive data integrity strategy. For instance, you might want to consider how data integrity relates to file sizes, and how maintaining integrity could impact storage space. Learn more about Ensure Data Integrity Through Checksums and Validation in relation to file size management.
The benefits of employing checksum validation are substantial. Early detection of data corruption prevents further damage and potential data loss. Maintaining data authenticity ensures its legal admissibility, crucial for industries with strict compliance requirements. It also prevents the insidious problem of silent data corruption, where seemingly intact data contains hidden errors that can have far-reaching consequences. These practices directly support compliance with data integrity requirements stipulated by various regulations and standards.
However, implementing checksum validation also introduces some challenges. Storing checksums requires additional storage overhead, which must be factored into your archiving strategy. The verification process itself consumes computing resources and can impact performance, particularly with large datasets. Furthermore, the system requires systematic monitoring and maintenance to ensure its continued effectiveness.
Successful implementations of checksum validation are found in various fields. Digital preservation initiatives, such as those using PREMIS metadata standards, rely heavily on checksums to guarantee the long-term integrity of digital assets. Medical imaging archives, bound by strict regulations, use DICOM integrity checks based on checksums to maintain the fidelity of diagnostic images. Even legal discovery platforms are increasingly adopting blockchain-based integrity verification, leveraging checksums to ensure the immutability of evidence.
To effectively implement checksum validation within your data archiving best practices, consider these tips: Use SHA-256 or a higher-level hashing algorithm for robust cryptographic security. Store checksums separately from the archived data to prevent them from being corrupted along with the data itself. Implement automated verification schedules based on data criticality. Finally, document and thoroughly test your data recovery procedures, ensuring that data can be restored reliably in case corruption is detected. This proactive approach ensures that your archived data remains trustworthy and accessible, fulfilling its intended purpose and safeguarding your organization's valuable information assets. The adoption of these strategies by organizations like the Digital Preservation Coalition, the Library of Congress digital preservation team, CERN data preservation projects, and major cloud storage providers highlights the importance and widespread recognition of checksum validation in modern data archiving.
4. Maintain Comprehensive Metadata and Documentation
Effective data archiving isn't simply about storing files away; it's about ensuring that those files remain accessible, understandable, and usable long into the future. A critical component of this process is maintaining comprehensive metadata and documentation. This practice involves the systematic capture, storage, and maintenance of descriptive information about archived data, encompassing its context, structure, relationships, and technical specifications. Without this crucial information, data can quickly become an indecipherable digital wasteland, rendering your archiving efforts futile. This is why maintaining comprehensive metadata and documentation deserves its place among the best practices for data archiving.

Metadata encompasses various categories, each serving a specific purpose. Descriptive metadata answers the fundamental questions of what, when, who, and why, providing context about the data's creation and purpose. Technical metadata details the format, structure, and any dependencies the data might have, essential for proper access and interpretation. Administrative metadata documents rights management information and any preservation actions taken, ensuring compliance and long-term accessibility. Structural metadata defines relationships and hierarchies within the data, especially relevant for complex datasets. All this metadata ideally resides within a searchable repository, further enhancing discoverability.
Implementing comprehensive metadata and documentation brings numerous benefits. It enables efficient data discovery and retrieval, saving valuable time and resources. Imagine needing to locate a specific dataset from five years ago – without proper metadata, this could be a needle-in-a-haystack scenario. Robust metadata preserves context and meaning over time, ensuring that data remains interpretable even as technologies and personnel change. This is crucial for maintaining the integrity and value of the archived information. Furthermore, comprehensive metadata supports compliance and audit requirements, allowing organizations to demonstrate proper data governance and adhere to regulatory obligations. Finally, it facilitates data migration and format conversion by providing essential information about the data’s structure and dependencies, simplifying the process of transferring data to new systems or updating file formats.
While the benefits are clear, implementing and maintaining metadata comes with challenges. It requires a significant investment of time and resources to establish appropriate schemas, capture metadata accurately, and ensure its ongoing maintenance. Metadata can quickly become outdated without regular updates, rendering it inaccurate and misleading. Moreover, managing large volumes of metadata might necessitate specialized tools and expertise. However, the long-term benefits of maintaining comprehensive metadata far outweigh these initial costs.
Many organizations have successfully implemented comprehensive metadata practices, showcasing its effectiveness in various contexts. The National Archives utilizes the Dublin Core metadata standards for describing and preserving historical records, enabling researchers and the public to access valuable information. Scientific research repositories leverage DataCite metadata to facilitate data sharing and collaboration across disciplines. Even corporate archives implement custom metadata schemas tailored to their specific business records, ensuring that valuable business intelligence remains accessible and usable. These examples demonstrate the adaptability and value of metadata across diverse fields.
To effectively implement metadata and documentation within your organization, consider these actionable tips. First, whenever possible, utilize standardized metadata schemas like Dublin Core. This promotes interoperability and simplifies data exchange. Automate metadata capture where feasible to streamline the process and reduce manual effort. You can Learn more about Maintain Comprehensive Metadata and Documentation relating to specific file types. Ensure to include business context and decision rationale within your metadata to provide valuable insights into the data’s origins and purpose. Finally, regularly review and update your metadata standards to reflect evolving best practices and business needs.
By implementing comprehensive metadata and documentation as part of your data archiving strategy, you ensure that your valuable information remains discoverable, understandable, and usable for years to come. While the initial investment may seem substantial, the long-term benefits of preserved context, improved data management, and enhanced compliance make it a vital aspect of any robust data archiving best practice.
5. Implement Geographic Distribution and Redundancy
A cornerstone of robust data archiving best practices is the implementation of geographic distribution and redundancy. This resilience strategy involves replicating and storing archived data across multiple geographically dispersed locations, ensuring data remains available even in the face of localized disasters, regional outages, or other catastrophic events. It’s a crucial step in ensuring business continuity and mitigating the risk of data loss. Simply put, don't put all your eggs in one basket – or one data center.
Geographic distribution and redundancy works by creating multiple copies of your archived data and storing them in physically separate locations. These locations should ideally be far enough apart (100+ miles is a common guideline) that a single regional event, like a natural disaster or major power outage, is unlikely to impact all of them simultaneously. This separation introduces a layer of fault tolerance that protects your valuable data assets. The process typically involves automated replication technologies that synchronize data across these locations, ensuring consistency and minimizing the risk of data divergence.
This approach relies on several key features:
- Multi-region data replication: Data is copied and maintained across multiple geographic regions.
- Geographic separation: Locations are chosen with sufficient distance to minimize shared risk.
- Automated failover capabilities: In the event of an outage in one location, operations automatically switch to a secondary location with minimal disruption.
- Cross-region backup synchronization: Mechanisms are in place to ensure data consistency across all locations.
- Disaster recovery testing procedures: Regular testing is conducted to validate the effectiveness of the geographic distribution and redundancy strategy.
The benefits of implementing geographic distribution and redundancy are substantial:
- Protection against regional disasters: Earthquakes, floods, fires, and other regional events are less likely to impact all data copies simultaneously.
- Improved data availability and access speeds: Data can be accessed from the closest geographic location, reducing latency for users in different regions.
- Enhanced business continuity: Operations can continue uninterrupted even in the event of a disaster, minimizing downtime and financial losses.
- Compliance with geographic data residency requirements: Some industries and regulations mandate storing data within specific geographic boundaries. This strategy helps meet these requirements.
While the advantages are significant, there are some potential drawbacks to consider:
- Higher storage and bandwidth costs: Maintaining multiple copies of data across different locations naturally increases storage and data transfer costs.
- Increased complexity in data management: Managing and synchronizing data across multiple locations adds complexity to data management processes.
- Potential latency issues for synchronization: Data synchronization across vast distances can introduce latency, especially for real-time applications.
- Regulatory challenges with cross-border data storage: Storing data across international borders can introduce legal and regulatory challenges related to data sovereignty and privacy.
There are numerous real-world examples of organizations leveraging geographic distribution and redundancy:
- Financial institutions: Banks and investment firms utilize multi-region cloud storage to archive transaction data and ensure regulatory compliance.
- Government agencies: Government bodies maintain geographically distributed backup sites to safeguard critical public data.
- Global corporations: Multinational companies implement cross-continental data mirroring to maintain data availability and access for their global operations.
To effectively implement geographic distribution and redundancy as part of your data archiving best practices, consider the following tips:
- Choose locations with different risk profiles: Don’t just choose locations that are geographically distant; consider factors like political stability, infrastructure reliability, and susceptibility to different types of natural disasters.
- Implement automated replication with monitoring: Automate the data replication process and implement robust monitoring to ensure data consistency and identify any potential issues promptly.
- Test disaster recovery procedures regularly: Conduct regular disaster recovery drills to validate your recovery plan and ensure your team is prepared to respond effectively in a real-world scenario.
- Consider data sovereignty and regulatory requirements: Carefully research and comply with all relevant data sovereignty and privacy regulations, especially when storing data across international borders.
Popular cloud providers offer services that simplify implementing geographic distribution and redundancy. These include Amazon Web Services (Cross-Region Replication), Microsoft Azure (Geo-redundant storage), Google Cloud (Multi-regional storage), and IBM Cloud (Geographic distribution). These services provide the infrastructure and tools to replicate and manage data across multiple regions, making it easier for organizations to adopt this critical data archiving best practice.
6. Regular Testing and Validation of Archive Accessibility
A critical component of any robust data archiving strategy is the regular testing and validation of archive accessibility. This proactive approach involves systematically testing the ability to retrieve, access, and use archived data to ensure it remains viable and accessible when needed. This practice, a core tenet of data archiving best practices, identifies potential issues before they escalate into critical, and potentially irreversible, problems, saving time, resources, and potentially even reputations. Simply storing data away is not enough; you must ensure it can be retrieved and utilized when required.
Regular testing and validation operates on the principle that archived data isn't static. Storage media degrades, software becomes obsolete, file formats evolve, and institutional knowledge fades. Without periodic checks, organizations risk discovering data inaccessibility only when the information is critically needed – a scenario that can have severe consequences. By implementing a structured testing regime, organizations gain confidence in their archive's reliability and can proactively address emerging challenges.
This crucial aspect of data archiving best practices encompasses several key features:
- Scheduled retrieval testing: Establishing a regular schedule for retrieving sample data from the archive, verifying its integrity and completeness.
- Format validation and readability checks: Confirming that archived data remains readable and usable in its intended format. This is especially important for older file formats that may require specific software or hardware for access.
- Performance benchmarking: Measuring the speed and efficiency of data retrieval to identify potential bottlenecks or performance degradation over time.
- Restoration procedure verification: Testing the entire data restoration process, including disaster recovery procedures, to ensure data can be fully recovered in emergency situations.
- Documentation of test results and issues: Maintaining detailed records of all testing activities, including results, identified issues, and remediation steps taken. This documentation provides valuable insights into the archive's health and informs future archiving strategies.
Implementing regular testing and validation offers numerous benefits:
- Early identification of access problems: Detecting issues like media degradation, software incompatibility, or format obsolescence before they impact business operations.
- Validates disaster recovery procedures: Provides assurance that critical data can be recovered in the event of a disaster, minimizing downtime and data loss.
- Ensures data remains usable over time: Confirms that archived data remains accessible and usable despite technological changes, preserving its long-term value.
- Builds confidence in archive reliability: Demonstrates the integrity and accessibility of archived data, instilling trust in the archiving process.
However, there are also some challenges associated with implementing this practice:
- Resource-intensive testing procedures: Testing can be time-consuming and require dedicated staff and resources.
- Potential costs for data retrieval during testing: Retrieving large datasets from certain archive types (e.g., deep storage) can incur costs.
- May require specialized tools and expertise: Advanced testing scenarios may necessitate specialized software and skilled personnel.
Examples of successful implementation across various sectors highlight the importance of regular testing and validation:
- Libraries: Libraries often conduct annual accessibility tests on their digital collections to ensure long-term preservation and access to valuable historical documents and research materials.
- Insurance companies: Insurance companies regularly validate their claims data retrieval procedures to ensure they can quickly access historical data for audits, investigations, and customer service requests.
- Research institutions: Research institutions diligently verify the long-term accessibility of their datasets to ensure the reproducibility of research findings and support future scientific inquiries.
To effectively implement regular testing and validation within your organization, consider the following tips:
- Develop automated testing scripts where possible: Automate repetitive testing tasks to improve efficiency and reduce manual effort.
- Test different retrieval scenarios and use cases: Simulate various data access scenarios to ensure the archive can meet diverse user needs.
- Document and track testing results over time: Maintain a comprehensive log of testing activities to monitor archive health and identify trends.
- Include end-user perspective in testing procedures: Incorporate feedback from end-users to ensure the archive meets their practical requirements.
Organizations like the Digital Preservation Coalition, the National Digital Information Infrastructure and Preservation Program (NDIIPP), the LOCKSS (Lots of Copies Keep Stuff Safe) project, and the DuraSpace organization have been instrumental in popularizing and promoting best practices in digital preservation, including the crucial role of regular testing and validation. By embracing these data archiving best practices, organizations can ensure their valuable data remains accessible and usable for years to come.
7. Format Migration and Future-Proofing Strategies
Format migration and future-proofing are crucial data archiving best practices that ensure long-term accessibility and usability of your valuable information. This preservation approach involves proactively converting archived data to current, standardized formats and planning for future format migrations to counteract the inevitable march of technological evolution. Ignoring this aspect of data archiving is like burying a time capsule without a map; future generations might find it, but they won't have the tools to understand its contents.
This proactive approach to data management acknowledges that technology changes rapidly. File formats that are common today might be obsolete tomorrow, rendering your archived data inaccessible. By implementing a robust format migration strategy, you ensure that your data remains usable regardless of system upgrades, software changes, or the emergence of new technologies.
Format migration and future-proofing involve several key features:
- Regular Format Assessment and Planning: This includes regularly reviewing the formats of your archived data and identifying those at risk of obsolescence. A well-defined migration plan outlines the steps, timelines, and resources required for format transitions.
- Migration to Open, Standardized Formats: Prioritizing open and standardized formats minimizes the risk of vendor lock-in and improves interoperability. These formats are typically well-documented and supported by a broad range of software applications, increasing the likelihood of long-term accessibility.
- Preservation of Original Format Alongside Migrations: Whenever feasible, keeping the original format alongside the migrated version provides an invaluable backup and allows for comparison in case of data discrepancies during conversion.
- Format Risk Assessment and Monitoring: This involves continuously monitoring the technological landscape for emerging format obsolescence risks and proactively assessing the potential impact on your archived data.
- Version Control for Migrated Data: Implementing version control for migrated data allows you to track changes, revert to previous versions if necessary, and maintain a comprehensive history of format transitions.
The benefits of this approach are numerous:
- Ensures Long-Term Data Accessibility: By migrating to current formats, you avoid the problem of needing obsolete hardware or software to access your archived information.
- Reduces Dependency on Obsolete Technologies: This frees your organization from relying on outdated systems and reduces the associated maintenance costs and security risks.
- Maintains Data Usability Across System Changes: Format migration ensures that your data remains usable even when you upgrade your systems or migrate to new platforms.
- Supports Legal and Regulatory Compliance: Many industries have regulations regarding data retention and accessibility. Format migration helps ensure compliance with these requirements.
However, it's crucial to acknowledge the potential drawbacks:
- Potential Data Loss During Format Conversion: While rare, there's always a slight risk of data loss or corruption during the conversion process. Thorough testing and validation are essential to mitigate this risk.
- High Costs for Complex Migration Projects: Migrating large volumes of data or dealing with complex, proprietary formats can be expensive and resource-intensive.
- Requires Ongoing Monitoring and Planning: Format migration isn't a one-time task. It requires continuous monitoring, planning, and periodic updates to stay ahead of technological advancements.
- May Need Specialized Expertise for Certain Formats: Dealing with unusual or proprietary formats might require specialized expertise, adding to the complexity and cost of the migration process.
Several organizations have successfully implemented format migration strategies:
- National Archives migrating government records from legacy formats: This ensures the long-term preservation and accessibility of important historical documents.
- Museums converting digital art collections to preservation formats: This protects valuable digital artworks from format obsolescence and ensures they can be enjoyed by future generations.
- Corporations migrating email archives from proprietary to open formats: This improves data accessibility and reduces reliance on specific email clients.
When considering format migration and future-proofing, it's helpful to understand how new technologies are adopted within organizations and industries. This awareness can inform strategic decisions about when and how to transition to newer formats. For a deeper understanding of this process, explore the technology adoption life cycle as a helpful resource.
To successfully implement format migration as part of your data archiving best practices, consider these tips:
- Prioritize open, standardized formats for long-term preservation.
- Maintain original formats alongside migrations when possible.
- Develop detailed migration procedures and test them thoroughly before full implementation.
- Monitor format obsolescence risks regularly to proactively address potential issues.
By implementing a robust format migration strategy as part of your overall data archiving best practices, you ensure that your valuable information remains accessible, usable, and relevant for years to come.
8. Robust Security and Access Control Framework
A critical aspect of any data archiving best practices is establishing a robust security and access control framework. This involves implementing a comprehensive security approach that protects archived data through multiple layers of protection, including encryption, access controls, audit logging, and compliance monitoring, all while maintaining authorized accessibility for legitimate business needs. This isn't just a "nice-to-have"—it's a fundamental requirement for responsible data management, especially when dealing with sensitive or regulated information. Without a robust security framework, your archived data becomes vulnerable to breaches, unauthorized access, and potential legal ramifications, undermining the very purpose of archiving.
This multifaceted approach safeguards data integrity and confidentiality over time. It's crucial to remember that archived data, though less frequently accessed than active data, often contains highly sensitive information that requires even stricter security measures. A breach of archived data can be just as damaging, if not more so, than a breach of active data due to the potentially large volumes of information compromised. Therefore, incorporating robust security into your data archiving best practices is non-negotiable.
How it Works:
A robust security and access control framework operates on the principle of "defense-in-depth," layering multiple security measures to create overlapping protection. This typically includes:
- End-to-End Encryption: Encrypting data both at rest (when stored in the archive) and in transit (when being moved to or from the archive) ensures that even if unauthorized access occurs, the data remains unintelligible.
- Role-Based Access Control (RBAC): RBAC restricts access to archived data based on predefined roles and responsibilities within the organization. This ensures that only authorized individuals can access specific data sets, limiting the potential damage from insider threats or compromised accounts.
- Multi-Factor Authentication (MFA): MFA adds an extra layer of security by requiring multiple authentication methods, such as a password and a one-time code, to access archived data. This significantly reduces the risk of unauthorized access even if credentials are compromised.
- Comprehensive Audit Logging: Detailed audit logs track all access attempts and actions performed on archived data, providing a crucial audit trail for accountability and forensic investigations in case of security incidents.
- Regular Security Assessments and Updates: Continuous monitoring and regular security assessments identify vulnerabilities and ensure that security measures remain effective against evolving threats. Regular updates to security software and protocols are essential for maintaining a strong security posture.
Examples of Successful Implementation:
The importance of a robust security framework is recognized across various sectors:
- Healthcare: Healthcare organizations implement HIPAA-compliant archive security measures to protect patient health information (PHI). This includes encryption, access controls, and audit logging to ensure data confidentiality and integrity.
- Finance: Financial institutions utilize encrypted archives for sensitive customer data, such as account numbers, transaction histories, and credit card information, complying with regulations like PCI DSS.
- Government: Government agencies implement stringent security protocols, often including classified data archive protection, to safeguard sensitive national security information.
Actionable Tips for Readers:
Implementing a robust security and access control framework requires careful planning and execution:
- Implement defense-in-depth security strategies: Combine multiple security layers for comprehensive protection.
- Use hardware security modules (HSMs) for key management: HSMs provide secure storage and management of encryption keys, protecting them from compromise.
- Regularly review and update access permissions: Ensure that access rights are aligned with current roles and responsibilities. Remove access for former employees or those who no longer require access.
- Maintain secure key backup and recovery procedures: Establish secure procedures for backing up and recovering encryption keys to prevent data loss in case of key compromise or system failure.
When and Why to Use This Approach:
A robust security and access control framework is essential whenever sensitive data is archived. This includes:
- Personally Identifiable Information (PII): Protecting data like names, addresses, social security numbers, and medical records.
- Financial Data: Safeguarding credit card information, bank account details, and transaction histories.
- Intellectual Property: Securing trade secrets, patents, and copyrighted materials.
- Regulated Data: Complying with industry-specific regulations like HIPAA, GDPR, and PCI DSS.
By prioritizing a robust security and access control framework within your data archiving best practices, you can effectively mitigate risks, maintain compliance, and ensure the long-term integrity and confidentiality of your valuable archived data. Organizations influenced by the NIST Cybersecurity Framework, ISO 27001 security standards, and the Cloud Security Alliance, along with guidance from major cybersecurity vendors like Symantec, McAfee, and Palo Alto Networks, have popularized and standardized many of these practices, demonstrating their widespread acceptance and effectiveness.
8 Key Data Archiving Best Practices Comparison
| Best Practice | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes 📊 | Ideal Use Cases 💡 | Key Advantages ⭐ |
|---|---|---|---|---|---|
| Establish Clear Data Lifecycle Management Policies | High – requires planning, coordination across teams | Significant – tools, legal/compliance involvement | Systematic, compliant data handling; reduced risks | Regulated industries, enterprises with complex data flows | Ensures compliance, reduces storage costs, improves governance |
| Implement Multi-Tier Storage Architecture | Medium to High – managing and automating tiers | Moderate – diverse storage solutions and monitoring | Cost-efficient storage with maintained accessibility | Organizations with large, varying access frequency data | Significant cost savings, scalable, optimized performance |
| Ensure Data Integrity Through Checksums and Validation | Medium – setting up cryptographic processes and monitoring | Moderate – storage for checksums, verification compute | Early corruption detection; data authenticity maintained | Legal, medical, scientific archives | Maintains data integrity, supports compliance, prevents silent corruption |
| Maintain Comprehensive Metadata and Documentation | Medium to High – continuous metadata capture and updates | High – tools, expertise, ongoing maintenance | Improved data discoverability and meaningful context retention | Archives, research data repositories, compliance-driven | Efficient retrieval, preserves context, aids compliance |
| Implement Geographic Distribution and Redundancy | High – complex multi-region replication and sync | High – storage, bandwidth, monitoring | Enhanced availability, disaster resilience, compliance | Enterprises needing business continuity and resilience | Protects against disasters, improves availability, ensures continuity |
| Regular Testing and Validation of Archive Accessibility | Medium – requires scheduled tests and reporting | Moderate – testing tools, staff time | Early issue detection; ensures archive usability | Libraries, insurance, research institutions | Builds confidence, validates recovery, detects access issues |
| Format Migration and Future-Proofing Strategies | High – ongoing format assessment and migration planning | High – conversion tools, expertise | Long-term data usability and compliance | Organizations with legacy data, digital preservation | Ensures long-term access, reduces obsolescence risk |
| Robust Security and Access Control Framework | High – multi-layered security implementation | High – encryption, access controls, audits | Strong data protection and compliance | Sensitive data environments: healthcare, finance, gov | Protects confidentiality, ensures compliance, provides audits |
Ready to Implement These Best Practices?
Effectively archiving your data isn't just about ticking boxes; it's about ensuring the long-term accessibility, security, and usability of your valuable information. By implementing these data archiving best practices—from establishing clear lifecycle management policies to incorporating robust security frameworks and future-proofing strategies—you're building a foundation for informed decision-making, efficient operations, and reduced storage costs. Remember, the key takeaways here are to proactively manage your data's lifecycle, prioritize integrity and accessibility, and plan for the future. Mastering these concepts empowers you to leverage your data as a strategic asset, enabling you to extract maximum value while mitigating risks.
These best practices, coupled with the right tools, can transform your data archiving strategy. Whether you're a corporate professional streamlining file management, a Mac user seeking advanced compression tools, or a content creator prioritizing quality preservation, efficient data archiving is paramount.
For Mac users seeking to optimize their archiving process, Compresto offers advanced compression technology to minimize storage footprint while maintaining file quality and accelerating transfer speeds. Streamline your data archiving workflow and maximize your storage efficiency. Download Compresto today at Compresto and experience the difference.